
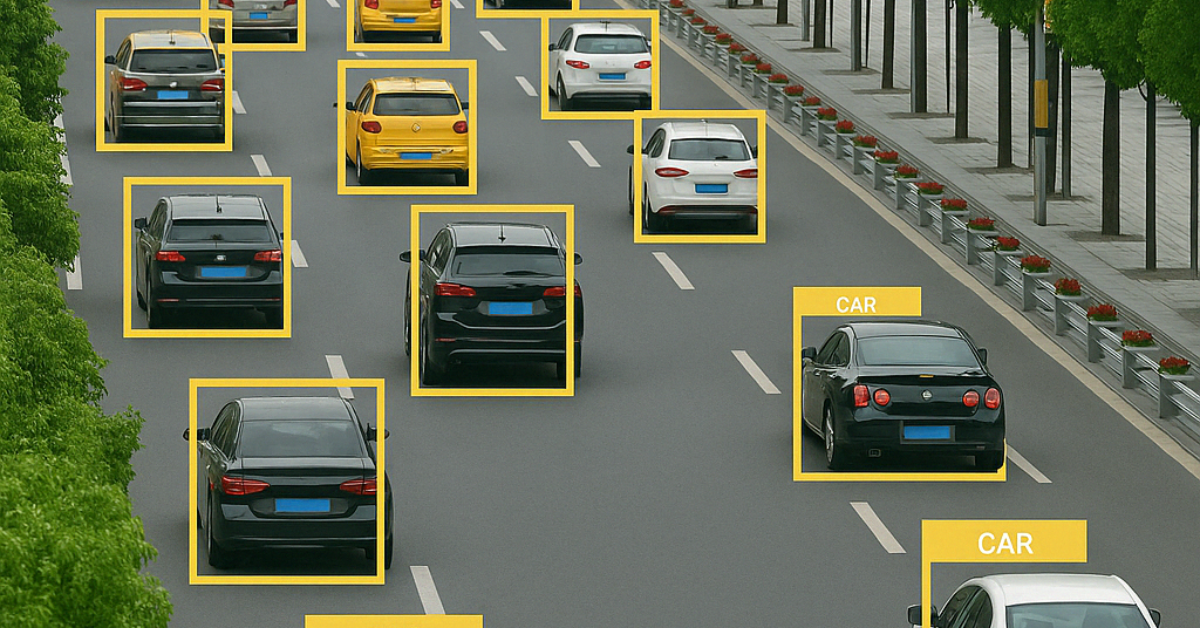
When 92% of AI and ML models rely on high-quality labeled data for optimal performance, it’s clear that data labeling isn’t just important—it’s fundamental. From powering autonomous vehicles to revolutionizing natural language processing, accurate labeled data forms the backbone of supervised learning models. Yet, the methods used to label data have evolved significantly, presenting new challenges and opportunities for machine learning engineers, AI researchers, and data scientists.
This blog will explore the evolution of data labeling, from traditional crowdsourcing to automation and hybrid approaches. By the end, you’ll have a thorough understanding of the different methods, their advantages and limitations, along with insights into future trends shaping the industry.
What is Data Labeling and Why Does it Matter?
At its core, data labeling is the process of annotating raw data—including text, images, audio, and video—to make it usable for AI and ML models. For supervised learning to occur, models require labeled datasets to identify patterns, make predictions, and improve over time.
Consider self-driving cars, which require labeled data to recognize road signs, pedestrians, and vehicles in diverse environments. Similarly, healthcare models need meticulously annotated medical images to identify signs of diseases, while natural language processing (NLP) systems depend on labeled text to improve performance in translations, sentiment analysis, or chatbots.
Poor-quality labeling can directly hinder a model’s performance, making accurate labeling not just important—but critical. However, the challenge lies in efficiently creating large labeled datasets, especially as datasets grow in complexity and size.
Traditional Crowdsourcing Methods
What is Crowdsourcing?
Crowdsourcing, one of the earliest methods for data labeling, involves leveraging a large pool of human annotators to manually label data. Platforms like Amazon Mechanical Turk and Appen connect companies with freelancers across the globe, making it possible for businesses to tackle labeling tasks quickly and at scale.
Where Does Crowdsourcing Shine?
Crowdsourcing excels in tasks requiring human intuition or subjectivity. For instance:
- Sentiment Analysis: Humans understand cultural and contextual nuances better than machines, making this method particularly effective.
- Medical Imaging Annotation: Expert annotators, like radiologists, are required to provide meaningful insights for data.
- Social Media Moderation: Human annotators ensure accurate labeling when analyzing content that may be inappropriate or context-dependent.
The Limitations of Crowdsourcing
While effective, crowdsourcing isn’t without its challenges:
- Scalability: For vast datasets, coordination and timelines can be a bottleneck.
- Quality Control: Uneven skill levels among annotators may result in inconsistent labeling, requiring additional review.
- Cost Inefficiency: High reliance on manual effort can quickly become expensive for large-scale datasets.
Automation in Data Labeling
What is Automated Data Labeling?
Automation in data labeling uses machine learning models and other AI tools to speed up the annotation process. Unlike human-dependent methods, AI-based platforms like Macgence, Scale AI and Labelbox automatically classify and tag data based on predefined parameters.
Key Benefits of Automation
- Speed & Scalability: Automation can process thousands of datasets in a fraction of the time it would take human annotators.
- Cost Effectiveness: With significantly reduced reliance on manual labor, automation saves money on large-scale projects.
- Consistency: Machine-based labeling ensures uniform accuracy across datasets, removing human error.
The Challenges of Automation
Despite its advantages, automation cannot yet handle every data labeling scenario. Ambiguous tasks or datasets requiring deep contextual understanding often necessitate human supervision. Additionally, AI models used for automation must first be trained on labeled datasets, creating a chicken-and-egg problem.
Hybrid Approaches to Data Labeling
What is a Hybrid Approach?
Hybrid data labeling combines automated tools with human-in-the-loop systems to maximize efficiency and accuracy. The machine suggests label outputs, while humans oversee and refine the final annotations. This approach strikes the perfect balance between speed and precision.
Key Benefits of Hybrid Systems
- Greater Accuracy: Humans fine-tune results, especially in cases of uncertainty or ambiguity.
- Improved Efficiency: Machines handle repetitive tasks, leaving humans to focus on high-value decisions.
- Scalability: Hybrid systems scale well for diverse datasets without sacrificing quality.
Prominent Examples
- Sama integrates social impact commitments with hybrid labeling, offering expert annotators supported by AI.
- Macgence emphasizes scalability by blending automated systems with human expertise, ensuring label quality for complex projects.
Spotlight on Industry Leaders in Data Labeling
1. Macgence
Standing out for its hybrid model, Macgence focuses on combining automation and human refinement, ensuring high-quality results for challenging datasets.
2. Scale AI
Known for its focus on AI-managed workflows, Scale AI provides powerful automated labeling solutions. Their technology is designed for projects requiring high-speed labeling without compromising accuracy.
3. Appen
Appen excels in crowdsourcing, leveraging a global workforce to provide premium annotation services. Recently, they’ve integrated AI to enhance their scalability.
4. Labelbox
A cloud-based platform, Labelbox offers robust AI-driven automation alongside tools for collaborative annotations, making it a favorite for data science teams.
5. Sama
Sama emphasizes social impact, using human-in-the-loop systems to benefit both AI projects and developing communities.
Future Trends in Data Labeling
1. Active Learning
Active Learning allows AI to suggest the most valuable data points for labeling, minimizing human involvement and maximizing efficiency.
2. Transfer Learning
By reusing labeled data from one domain for another, Transfer Learning accelerates labeling for datasets in similar fields.
3. Zero-shot Learning
Zero-shot learning enables models to perform labeling tasks with minimal annotated data, leveraging pre-trained systems for incredible efficiency.
4. Ethical AI and Transparency
As AI expands, the industry will need to adopt stricter ethical guidelines to ensure transparency in labeling processes, including reducing inherent biases in labeled data.
Building Smarter Models with Smarter Data Labeling
The evolution of data labeling—from basic crowdsourcing to advanced hybrid approaches—is revolutionizing the way AI and ML models are trained. For professionals working with machine learning, understanding these methods is crucial to choosing the right approach for your specific projects. Whether you’re dealing with high-volume datasets or nuanced labeling challenges, the right solutions can drastically improve your model’s performance.
To stay ahead, explore platforms like Macgence, Scale AI, Labelbox, and Sama or experiment with hybrid approaches that combine the best of both human and machine capabilities. Knowledge is power, and in the world of AI, the right data is everything.
FAQs
Ans: – This refers to the complete framework of methods, tools, and stakeholders involved in annotating data for machine learning and AI applications. It includes manual labeling, crowdsourcing, automated labeling, and hybrid approaches, along with the platforms and technologies that support these efforts.
Ans: – Crowdsourcing in data labeling involves outsourcing annotation tasks to a distributed group of workers, often through online platforms. These contributors label data such as images, text, or audio, making it usable for training AI models. It’s a scalable and cost-effective method, especially for large datasets.
Ans: – Automated labeling offers speed, scalability, and cost savings. By using machine learning models or heuristics to generate labels, automation reduces the dependency on human annotators. However, it often requires quality assurance checks to ensure accuracy.
Ans: – Hybrid labeling is gaining popularity because it balances the precision of human input with the efficiency of automation. It allows faster processing of large datasets while maintaining high-quality annotations through human oversight and corrections.
Ans: – Quality control in labeling ensures that the annotated data is accurate, consistent, and reliable. Techniques like consensus labeling, gold standard data, and review loops are used to maintain high-quality outputs, especially in large-scale or crowdsourced projects.
Ans: – AI enhances labeling by automatically generating initial labels, performing active learning, and identifying edge cases that need human review. It accelerates the labeling process and helps maintain consistent accuracy across datasets.

I am passionate about helping businesses grow their online presence and achieve measurable results. Let’s connect and discuss how I can help you reach your digital marketing goals!


